 |
|
|
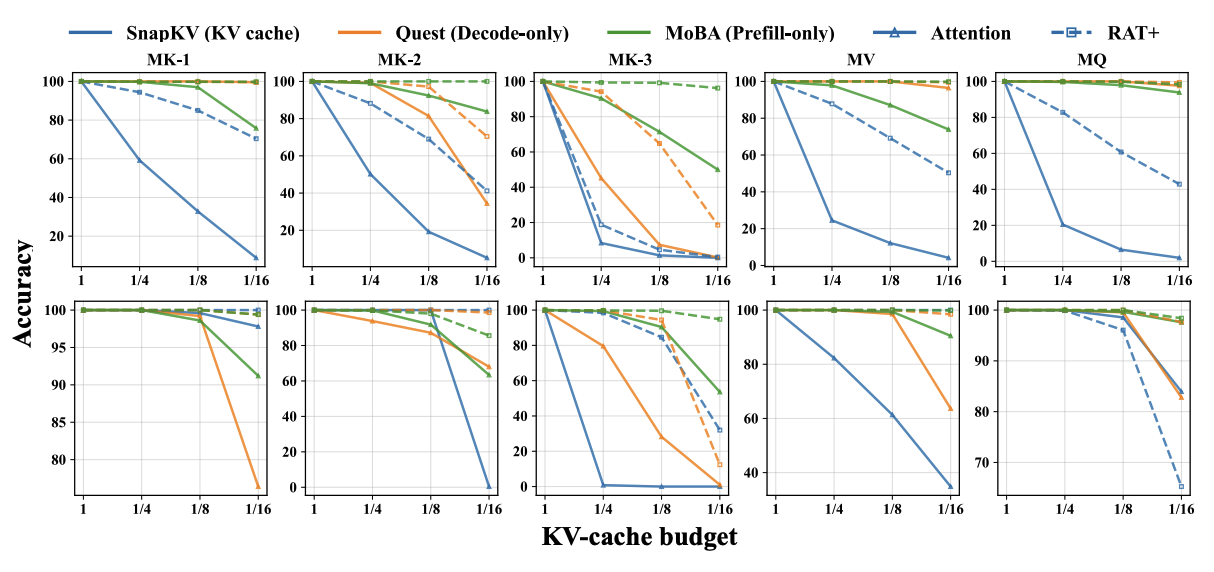 |
Augmenting Attention with Exponentially Decaying Memory Improves Query-Aware KV Sparsity Step 3: In this 4-page paper, we demonstrate that our dense RAT+ also significantly benefits existing query-aware sparsity methods (such as Quest, MoBA, and SnapKV) compared to applying them to a standard attention. Our work sheds new light on efficient LLM inference: instead of focusing solely on optimizing downstream inference-time algorithms, we can design upstream architectures that are inherently more compatible with sparse inference—offering native support for dilated patterns and superior results on query-aware sparse patterns. |
|
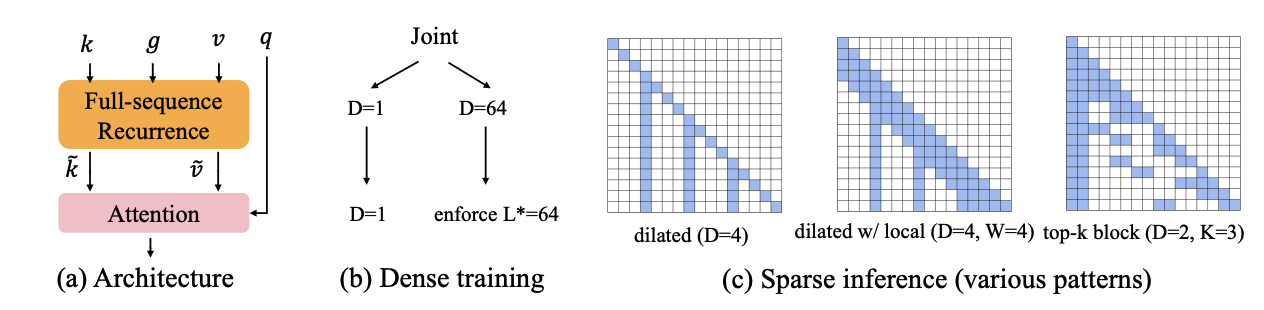 |
RAT+: Train Dense, Infer Sparse - Recurrence Augmented Attention for Dilated Inference Step 2: Compared to RAT, this paper takes a step further. Instead of pretraining a sparse architecture with fixed hyperparameter configurations (such as chunk size, dilation size, and compression ratio), we propose to pretrain densely once, then switch flexibly during inference to various dilated attention patterns (e.g., local windows) or hybrid layer/head compositions. Our dense architecture simply augments attention with recurrence and an active learning. The reason to use it: 1) It can drastically reduce KV cache with comparable accuracy —a feat that existing methods like GQA (train-from-scratch) or StreamingLLM (inference-time sparsity) cannot achieve. 2) Unlike models with fixed pretrained architectures (e.g., DeepSeek-V4), ours natively supports flexible inference-time compression. |
|
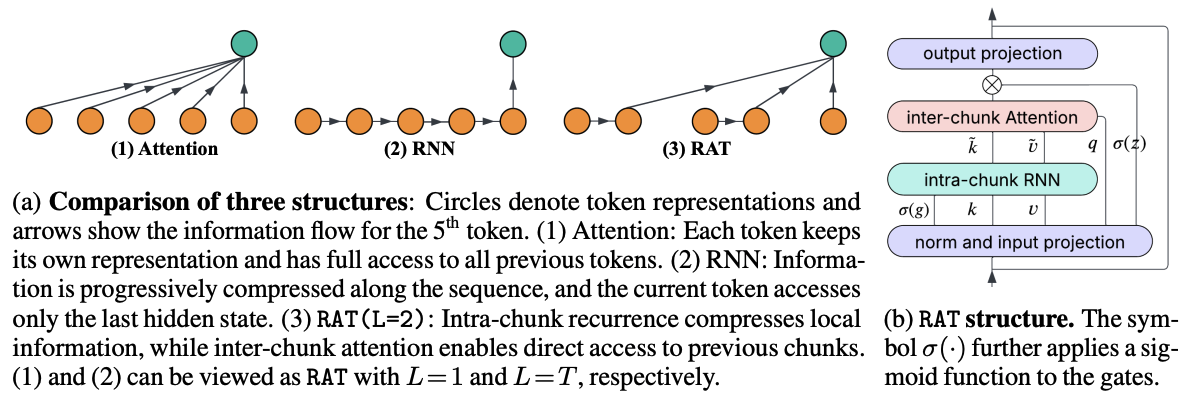 |
RAT: Bridging RNN Efficiency and Attention Accuracy via Chunk-based Sequence Modeling Step 1: RNNs compress the entire sequence into a fixed-size hidden state, which is fast but lossy, whereas attention applies no compression, making it accurate but slow. RAT introduces an intermediate architecture that splits the sequence into multiple short chunks, applies recurrence within each chunk for KV compression, and then performs inter-chunk attention. RAT(L=16) achieves good balance of accuracy and efficiency. We refer to our inter-chunk attention as dilated attention in a follow-up work. |
|
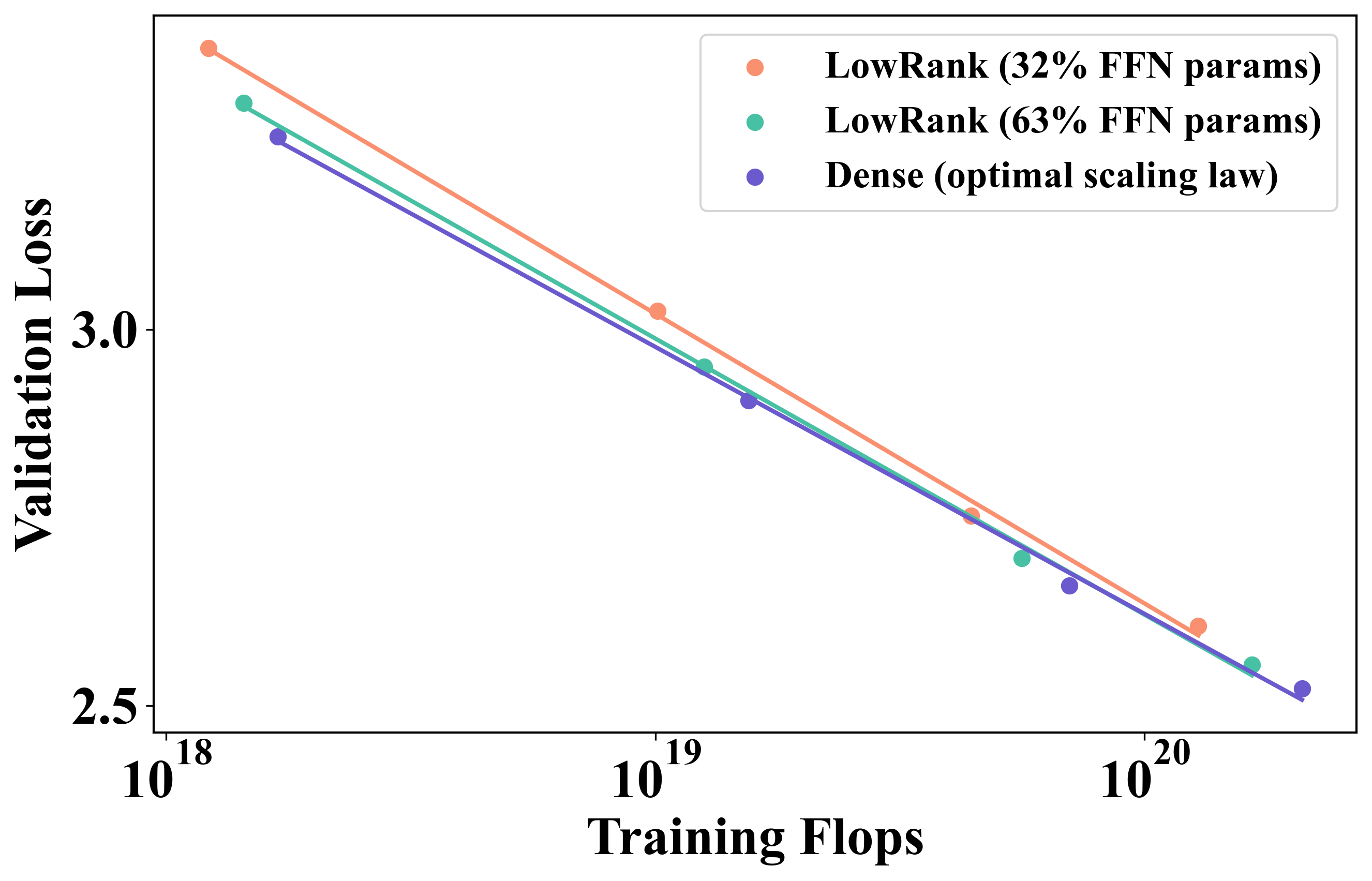 |
Building on Efficient Foundations: Effectively
Training LLMs with Structured Feedforward Layers Investigate three structured linear parameterizations in transformer language models: 1)scaling law study and model size scaling, 2)efficiency and pre-merge technique, 3)optimization and self-guided training [Paper] [Code] |
|
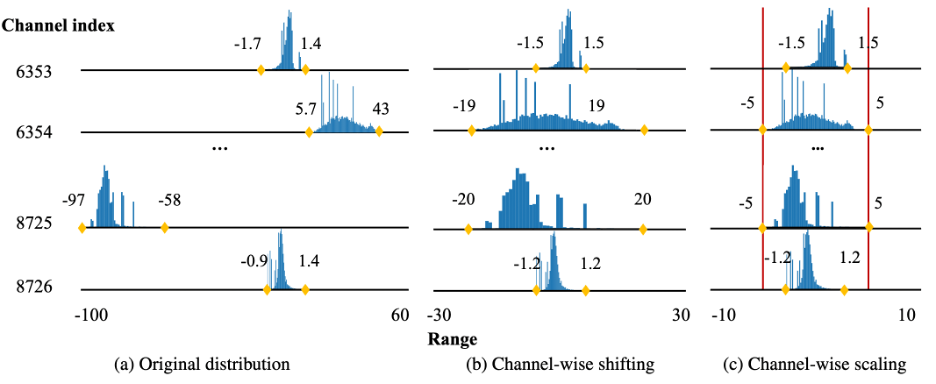 |
Outlier Suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling |
|
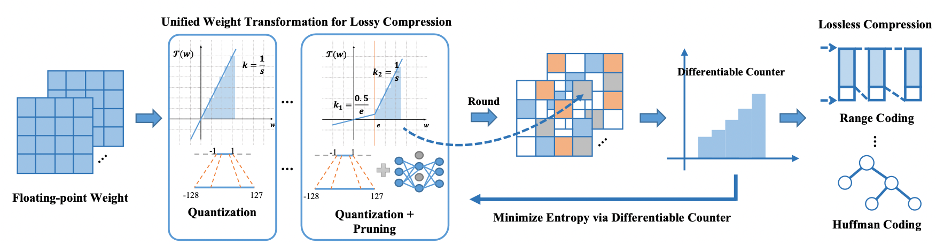 |
Lossy and Lossless (L2) Post-training Model Size Compression Integrate lossless and lossy compression techniques in a post-training setting. [Paper] |
|
 |
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models Identify outlier phenomenons (channel concentration and token discrepancy) for quantizing transformer language models. Propose a framework to suppress these outliers. [Paper] [Code] |
|
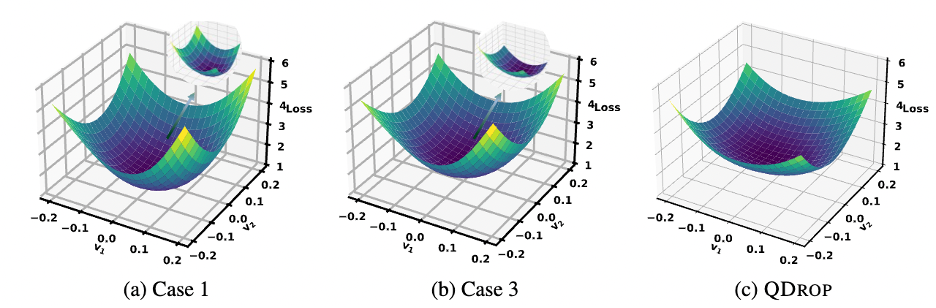 |
QDrop: Randomly Dropping Quantization For Extremely Low-bit Post-training quantization. Investigate how the activation quantization affects weight tuning. Build the relationship between activation quantization and flatness of quantized weights. Propose to randomly drop the activation quantization to achieve a flatter optimized weights. [Paper] [Code] |
Honors and Awards
- Silver Medal of 44th ACM-ICPC Asia-East Continent Final, 2019
- Gold Medal of 5th China Collegiate Programming Contest, 2019
- Silver Medal of 43rd ACM-ICPC Asia-East Continent Fina, 2018
- Gold Medal of 43rd ACM-ICPC Asia Regional Contest (Qingdao Site), 2018
- Gold Medal of 43rd ACM-ICPC Asia Regional Contest (Nanjing Site), 2018
- Silver Medal of 4th China Collegiate Programming Contest, 2018
I love sports, including going to the gym, swimming, and cycling (as a beginner). I also love cooking and reading a lot of novels.