 |
|
|
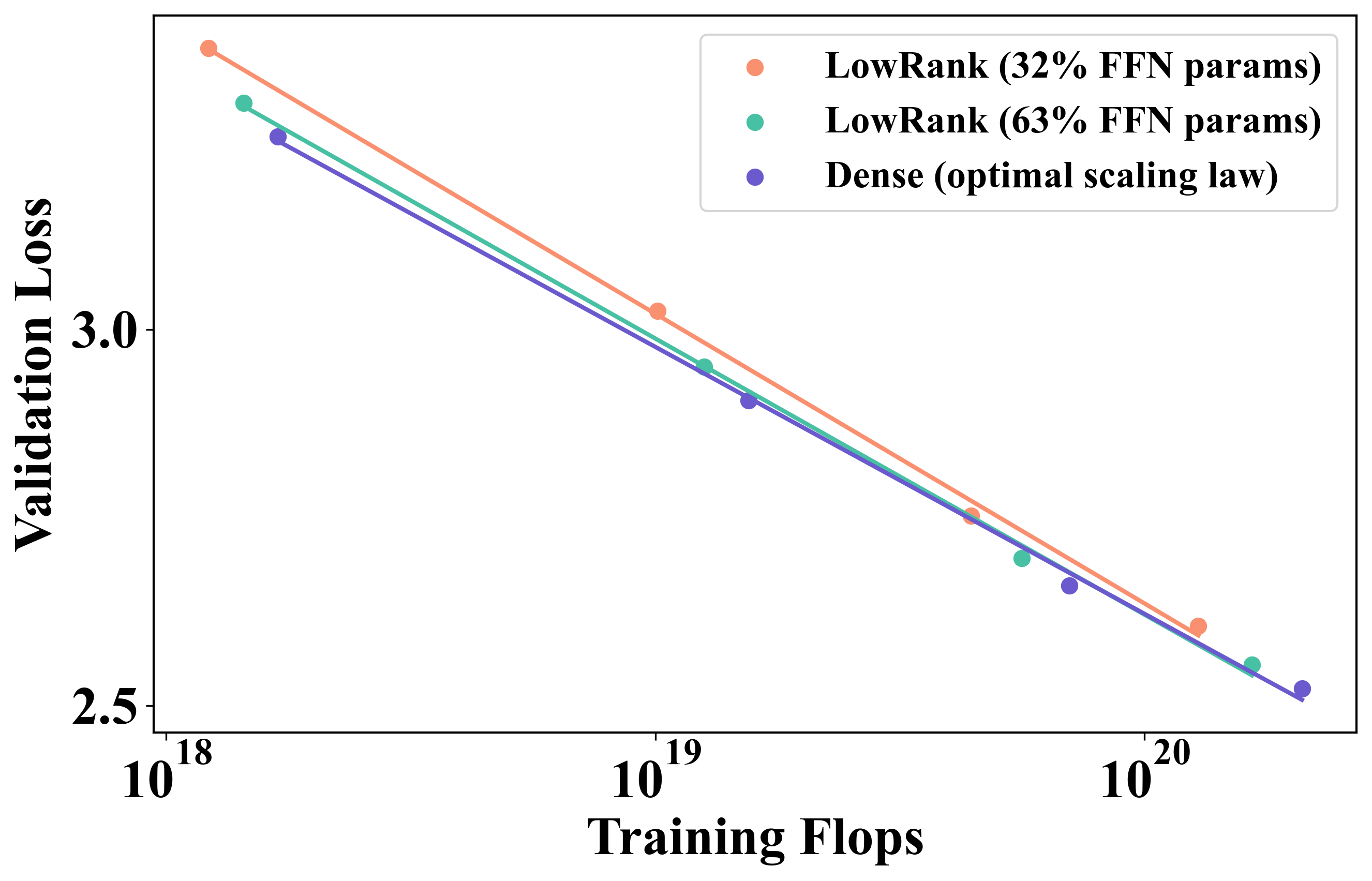 |
Building on Efficient Foundations: Effectively
Training LLMs with Structured Feedforward Layers Investigate three structured linear parameterizations in transformer language models: 1)scaling law study and model size scaling, 2)efficiency and pre-merge technique, 3)optimization and self-guided training [Paper] [Code] |
|
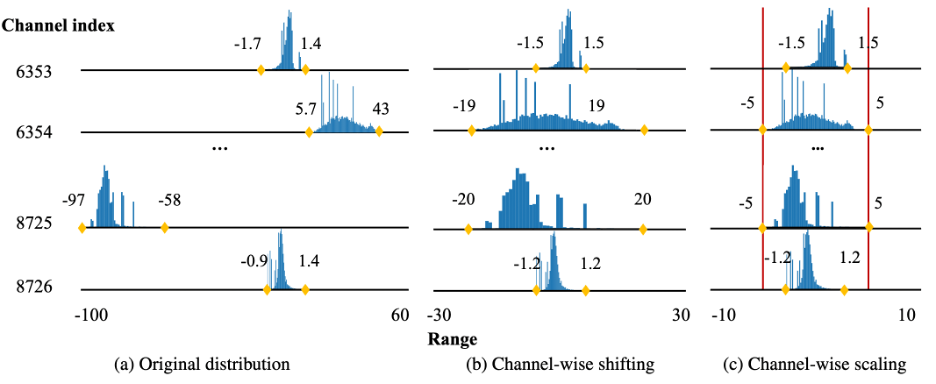 |
Outlier Suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling |
|
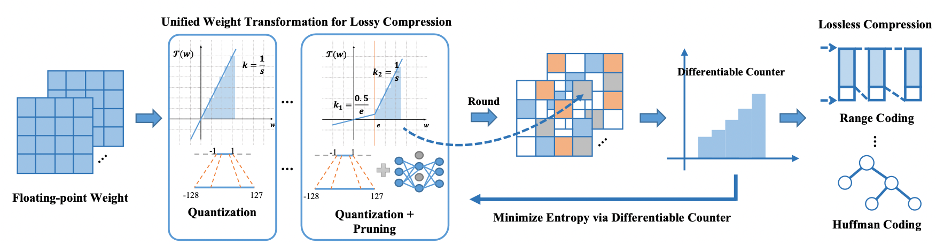 |
Lossy and Lossless (L2) Post-training Model Size Compression Integrate lossless and lossy compression techniques in a post-training setting. [Paper] |
|
 |
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models Identify outlier phenomenons (channel concentration and token discrepancy) for quantizing transformer language models. Propose a framework to suppress these outliers. [Paper] [Code] |
|
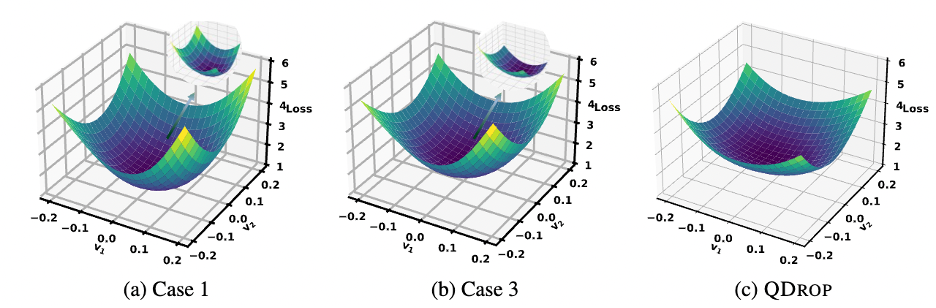 |
QDrop: Randomly Dropping Quantization For Extremely Low-bit Post-training quantization. Investigate how the activation quantization affects weight tuning. Build the relationship between activation quantization and flatness of quantized weights. Propose to randomly drop the activation quantization to achieve a flatter optimized weights. [Paper] [Code] |
Honors and Awards
- Excellent Master Dissertation Award of Beihang University, 2023
- SenseTime Annual Best Paper Award, 2022
- Silver Medal of 44th ACM-ICPC Asia-East Continent Final, 2019
- Gold Medal of 5th China Collegiate Programming Contest, 2019
- Silver Medal of 43rd ACM-ICPC Asia-East Continent Fina, 2018
- Gold Medal of 43rd ACM-ICPC Asia Regional Contest (Qingdao Site), 2018
- Gold Medal of 43rd ACM-ICPC Asia Regional Contest (Nanjing Site), 2018
- Silver Medal of 4th China Collegiate Programming Contest, 2018
In her spare time, she reads a lot of novels and loves to explore the lifestyle.